
ANS IG document core
0.1.0 - ci-build
![]()
ANS IG document core
0.1.0 - ci-build
![]()
ANS IG document core - version de développement local (v0.1.0) construite par les outils de publication FHIR (HL7® FHIR® Standard). Voir le répertoire des versions publiées
CDA® R2.0 est un standard de dématérialisation des documents médicaux électroniques exploitant la syntaxe XML.
Les documents au format CDA doivent respecter le standard CDA® R2.0 Online Edition 2024 (2024-08-20 Version Normative).
Un guide d’implémentation CDA® R2.0 Structure Definition Format produit par HL7 vient en support du standard.
Le standard CDA R2.0, par sa conception, permet de respecter les exigences spécifiques aux documents dématérialisés énoncées au paragraphe “Exigences spécifiques aux documents dématérialisés”.
Le standard CDA R2.0 permet de coupler dans un même document :
CDA R2.0 est comme son nom l’indique une architecture dédiée aux documents cliniques. Il est possible de construire, sur le schéma CDA_extended.xsd, des modèles de documents adaptés à la plupart des spécialités médicales et médico-sociales dans la plupart des contextes d’usage.
Un document XML conforme au standard CDA R2.0 se compose :
<component>| Prologue | <?xml version="1.0" encoding="UTF-8"?> |
| Racine | <ClinicalDocument xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:hl7-org:v3 ../infrastructure/cda/CDA_extended.xsd" xmlns="urn:hl7-org:v3" xmlns:pharm="urn:ihe:pharm:medication"> |
| Entête | <realmCode code="FR"/> <typeId root="2.16.840.1.113883.1.3" extension="POCD_HD000040"/> ... |
| Corps | <component> ... </component> |
</ClinicalDocument> |
Le prologue d’un document CDA R2 comporte :
L’encodage spécifié dans le prologue du document est obligatoirement UTF-8. C’est l’encodage par défaut pour un document XML.
<?xml version="1.0" encoding="UTF-8"?>
Les systèmes producteurs et les systèmes consommateurs doivent impérativement tenir compte de cet encodage et si nécessaire, réaliser le transcodage entre le contenu du document et leur encodage local, qui peut être différent.
La plupart des applications manipulant des documents textes (non XML) utilisent le codage ISO-8859-1 ou son successeur, le codage ISO-8859-15. Ces applications doivent donc réaliser le transcodage entre ces jeux de caractères ISO-8859 et le jeu UTF-8 des documents CDA.
En revanche, les contenus encapsulés en base 64 dans un corps non structuré d’un document CDA (par exemple un PDF) doivent conserver leur jeu de caractères initial.
La deuxième ligne annonce que le document est accompagné de sa propre feuille de style XSLT.
<?xml-stylesheet type="text/xsl" href="./nom-feuille-de-style.XSL"?>
<?xml-stylesheet type="text/xsl" href="#"?>
ClinicalDocument est l’élément racine d’un document médical au format CDA R2. Cet élément déclare les différents espaces de nommage utilisés.
Les éléments XML du document CDA appartiennent à l’espace de nommage HL7 V3, dont l’URL est “urn:hl7-org:v3”.
L’attribut “xsi:schemaLocation” qui fournit l’emplacement du schéma CDA_extended.xsd, n’est pas à renseigner. En effet, le système initiateur ne connaît pas l’emplacement du schéma sur le système cible.
Exemple :
<ClinicalDocument xmlns="urn:hl7-org:v3" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
Dans le cas d’un document CDA R2 signé électroniquement, la signature enveloppe le document.
L’élément racine est dans ce cas ds:Signature du standard xmldsig.
L’élément ClinicalDocument introduisant ses propres espaces de nommage est, dans ce cas de figure, un descendant de l’élément racine ds:Signature. La validation par rapport au schéma CDA_extended.xsd et par rapport aux schématrons ne s’applique qu’au sous-arbre ClinicalDocument.
La signature électronique du document CDA R2 est spécifiée au paragraphe 4.1 Imputabilité et intégrité du document médical.
Dans le cas d’un document CDA, le contenu CDA et la feuille de style sont juxtaposés dans un unique document XML dont l’élément racine est xsl:stylesheet. L’ensemble [feuille de style + contenu] peut éventuellement être signé électroniquement, ce qui ne change pas cet élément racine.
L’élément ClinicalDocument introduisant ses propres espaces de nommage est, dans ce cas de figure, un descendant de l’élément racine xsl:stylesheet. La validation par rapport au schéma CDA_extended.xsd et par rapport aux schématrons ne s’applique qu’au sous-arbre ClinicalDocument.
L’entête contient les informations générales et nécessaires à la gestion du document. Ces informations permettent de relier le document au contexte dans lequel il a été produit, de le classer dans les catégories adéquates et de gérer son évolution et son accessibilité dans la durée. La structure de base de l’entête est identique quel que soit le type de document et quel que soit le degré de structuration choisi. Les éléments de l’entête portent sur :
<section>).
Chacune de ces sections possède un type (élément <code>), un titre (élément <title>) et un bloc narratif (élément <text>).
En outre une section peut contenir des sous-sections (élément <section>) et des entrées (élément <entry>) fournissant les données du SI producteur à l’aide desquelles a été construit le bloc narratif. Ces données sont codées et structurées, importables et intégrables dans la base de données des SI consommateurs du document.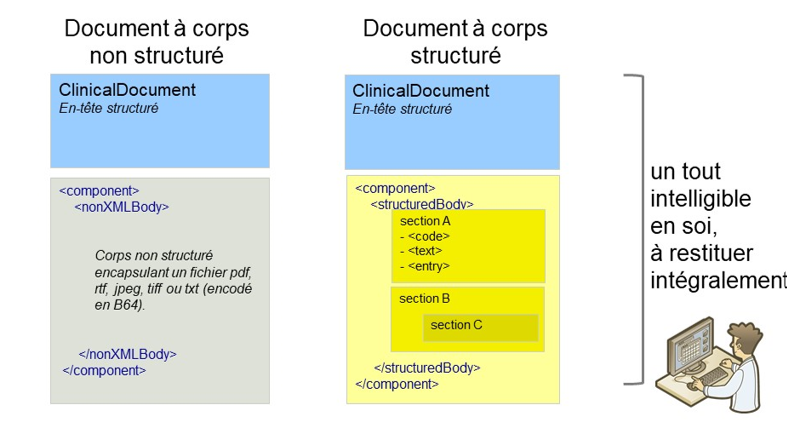
Les deux formes de documents CDA
Un document à corps non structuré est produit lorsqu’il n’existe pas de modèle structuré spécifié dans le CI-SIS pour le type de document produit.
Les informations DOIVENT être au format PDF ou TEXT. Les images (format jpeg et tiff) doivent d’abord être transformées en PDF/A-1.
Les informations sont encodées en base 64 et encapsulées dans l’élément fils nonXMLBody/text, qui est obligatoire (cardinalités [1..1] et attribut nullFlavor interdit).
ClinicalDocument/component/nonXMLBody/text contient les deux attributs suivants obligatoirement présents et renseignés :
Exemple :
<component>
<nonXMLBody>
<text mediaType="application/pdf" representation="B64">JVBERi0xLjUN… </text>
</nonXMLBody>
</component>
Si le contenu médical est dans une langue différente du français, annoncé par l’entête du document (ClinicalDocument/languageCode/@code=”fr-FR”), alors l’élément ClinicalDocument/component/nonXMLBody/languageCode doit être présent et doit préciser la langue utilisée dans le contenu encapsulé.
Un document à corps structuré DOIT être conforme à son modèle défini dans le volet de la couche Métier du CI-SIS qui précise les exigences syntaxiques (structure) et sémantiques (terminologies et jeux de valeurs pour coder les données) de ce document.
Les sections de 1er niveau sont dans l’élément fils structuredBody.
Exemple :
<component>
<structuredBody>
<!-- Section A -->
<component>
<section>
…
</section>
<!-- Section B -->
<component>
<section>
…
</section>
</component>
</structuredBody>
</component>
Les spécifications françaises des documents CDA définies dans le CI-SIS :
Les spécifications françaises de l’entête d’un document CDA du CI-SIS sont conformes aux spécifications internationales des données de l’entête d’un document médical décrites dans le Profil IHE XDS-SD du domaine IHE IT Infrastructure (ITI).
Elles sont communes aux CDA R2 niveau 1 (corps non structuré) et aux CDA R2 niveau 3 (corps structuré).
Elles portent essentiellement sur :
Les modèles de documents structurés français sont décrits dans des volets de contenu de la couche Métier.
Ils précisent les contraintes spécifiques de l’entête (modèle du document, type de document, participants, etc…).
Ils définissent les sections et entrées à utiliser et les terminologies ou jeux de valeurs à utiliser pour les données codées.
Les volets structurés de la couche Métier, s’appuient sur les modèles de contenus (sections et d’entrées), communs à l’ensemble des documents.
La majorité des modèles de contenu (sections et entrées) sont issus des spécifications IHE :
Lorsqu’aucun modèle n’est identifié dans les spécifications IHE pour répondre à un besoin spécifique du contexte français, un modèle spécifique est alors créé pour le contexte français.
Les sections sont les éléments qui composent le corps structuré d’un document CDA.
On distingue deux types de sections :
Une section atomique ne contient pas de sous-section.
Une section atomique contient zéro, une ou plusieurs entrées.
Une section composite est composée d’autres sections.
Une section composite ne comporte pas d’entrée, ni de bloc narratif (pas d’élément text) mais seulement une liste de sous-sections.
La structure générale d’une section est la suivante :
<component>
<section>
<!-- ① Déclaration(s) de conformité de la section (obligatoire) -->
<templateId root="…"/>
<!-- ② Identifiant unique de la section (optionnel) -->
<id root=" " extension=" "/>
<!-- ③ Code et libellé LOINC de la section (obligatoire) -->
<code code=" " displayName="" codeSystem="2.16.840.1.113883.6.1" codeSystemName="LOINC"/>
<!-- ④ Titre de la section -->
<title>titre de la section</title>
<!-- ⑤ Bloc narratif de la section destiné au lecteur (obligatoire) -->
<text> Compte-rendu de consultation... </text>
<!-- ⑥ Entrées de la section -->
<entry>
<templateId root="…"/>
:
</entry>
:
<!-- ⑦ Sous-sections de la section -->
<component>
<section>
:
</section>
</component>
:
</section>
</component>
① Déclaration(s) de conformité de la section.
Une section comporte une ou plusieurs déclarations de conformité obligatoires, chacune se présentant sous la forme d’un élément templateId dont l’attribut root contient l’OID du modèle concerné.
② Identifiant unique de la section (optionnel).
Dans un certain nombre de cas, un numéro unique d’identifiant, attaché à une section ou à une entrée, est requis. Cet élément est un UID attribué par l’application LPS.
Il s’agit :
Soit d’un OID et dans ce cas les attributs de l’élément <id> prennent les valeurs suivantes :
→ root: OID du document
→ extension: numéro d’identifiant de la section ou de l’entrée affecté par le LPS
Exemple <id root="OID du document' extension='id attribué par le LPS/>
Soit d’un UUID dans le cas où ces éléments viendraient à manquer. Dans ce cas cet identifiant est affecté à l’attribut root et l’attribut extension sera omis.
Exemple <id root=2BFB4077-C831-4C6E-8BBD-7368A6130182/>
Cet identifiant unique peut être utilisé comme référence dans une entrée FR-reference-interne.
⑤ Bloc narratif de la section
Le bloc narratif est obligatoire dans les sections atomiques.
Ce bloc narratif contient le texte destiné au lecteur. Il a valeur de référence légale.
La mise en forme du bloc narratif (contraintes de présentation) n’est pas spécifiée dans le présent volet. Ces contraintes de présentation sont, le cas échéant, précisées par les volets de contenus métiers.
⑥ Entrée(s) de la section lorsque la section n’est pas de type narratif pur.
Chaque entrée contient les données codées destinées au SIS consommateur.
Chaque entrée se conforme à un modèle dont l’OID est cité dans l’élément ⑥ templateId de l’entrée.
⑦ Sous-sections
Une section composite peut contenir un certain nombre d’autres sections.
La norme CDA permet d’indiquer de façon optionnelle la participation d’acteurs au niveau des sections et des entrées d’un document CDA structuré. Dans ce cas, ils remplacent les acteurs décrits au niveau supérieur.
Chaque entrée d’un document CDA peut avoir un (ou des) acteur(s). Si l’entrée ne contient pas d’acteur, les acteurs de l’entrée sont ceux indiqués dans la section. Si la section ne contient pas d’acteur, les acteurs de la section (et de l’entrée) sont les acteurs du document. C’est le principe de propagation du contexte, qui est une caractéristique du RIM HL7, et qui part du document vers les sections, sous-sections, entrées et sous-entrées emboitées.
Acteurs possibles dans les sections :
| Acteur | Card. | Description |
|---|---|---|
| author | [0..*] | Un élément <author> dans une section permet de décrire la participation d’un auteur (PS, dispositif, patient) à l’élaboration des données de la section. Les auteurs indiqués dans une section CDA remplacent les auteurs indiqués dans l’entête CDA. |
| informant | [0..*] | Un élément <informant> dans une section permet de décrire un PS, un ES, le patient lui-même ou une autre personne non PS ayant fourni des informations concernant les données de la section (rôle d’informateur). Les informateurs indiqués dans une section CDA remplacent les informateurs indiqués dans l’entête CDA. |
Acteurs possibles dans les entrées :
| Balise | Card. | Description |
|---|---|---|
| performer | [0..*] | Un élément <performer> dans une entrée permet de décrire la personne ayant exécuté l’acte décrit par l’entrée. Les exécutants indiqués dans une entrée CDA remplacent les exécutants indiqués dans la section CDA ou propagés de l’entête CDA. L’exécutant n’est pas toujours le participant principal responsable de l’acte. Par exemple, un interne en chirurgie est un exécutant qui opère sous la supervision du chirurgien responsable de l’acte. |
| author | [0..*] | Un élément <author> dans une entrée permet de décrire la participation d’un auteur (PS, dispositif, patient) à l’élaboration des données de l’entrée. Les auteurs indiqués dans une entrée CDA remplacent les auteurs indiqués dans la section CDA ou propagés de l’entête CDA. |
| informant | [0..*] | Un élément <informant> dans une entrée permet de décrire un PS, un ES, le patient lui-même ou une autre personne non PS ayant fourni des informations concernant les données de l’entrée (rôle d’informateur). Les informateurs indiqués dans une entrée CDA remplacent les informateurs indiqués dans la section CDA ou propagés de l’entête CDA. |
| participant | [0..*] | Un élément <participant> dans une entrée permet de décrire un PS ou un ES impliqué dans l’acte décrit par l’entrée et dont le rôle n’a pas été mentionné ailleurs (dans la section ou dans l’entête). Le participant peut être attribué à une entrée du CDA et se propage aux entrées imbriquées. |
La structure des éléments <author>, <informant> et <participant> est la même dans l’entête et dans le corps d’un document CDA.
La structure de l’élément <performer> utilisé dans l’entête est différente de la structure de l’élément <performer> utilisé dans le corps d’un document CDA.
Les règles de syntaxe de CDA permettent, pour une section donnée, de présenter l’information médicale sous un format texte et de l’accompagner, ou pas, de la même information codée.
La codification des données permet une meilleure intégration et exploitation de ces données médicales par les autres systèmes d’information consommateurs.
CDA permet de référencer des éléments du bloc narratif d’une section à partir des entrées de cette section.
Ce référencement se fait :
<content>, élément optionnel du bloc narratif de la section, permet de délimiter la zone de texte à référencer.ID de l’élément <content> est affecté d’un index de valeur unique dans le document, qui permet le référencement de la zone balisée.entry : Le composant <originalText/reference> permet de référencer explicitement la zone du bloc narratif référencée par <content> en pointant sur la valeur de l’index ID associé.
Exemple de référencement d'une zone de texte à partir d'un élément codé
Dans certains cas, pour les entrées codées, si le code d’une donnée n’est pas disponible, l’information peut être portée par la partie narrative (élément <text>) et l’entrée codée portera une référence vers la partie narrative.
Par exemple : dans l’entrée FR-Probleme, où l’élément <value> attend un élément codé :
<value> relatif au type de donnée restera xsi:type=’CD’,<value> relatifs au codage de la donnée code, displayName, codeSystem, codeSystemName ne seront pas présents,<originalText> <reference> indiquera la référence de l’information dans la partie narrative (élément <text>) comme décrit ci-dessus.
Exemple de référencement d'une zone de texte à partir d'un élément non codé
entryRelationship est un élément qui met en relation deux éléments de type Clinical statements (act, observation, procedure, etc.).
La nature de cette relation est définie par deux attributs, typeCode et inversionInd :
typeCode indique en quoi consiste cette relationinversionInd permet d’inverser cette relation.On considère que l’élément SOURCE est l’élément contenant la relation entryRelationship et l’élément TARGET est l’élément contenu dans l’entryRelationship :

Les valeurs utilisées pour caractériser un élément entryRelationship avec l’attribut typeCode sont :
| XRCPT | SOURCE résume TARGET |
| COMP | TARGET est un composant de SOURCE |
| RSON | TARGET est la raison de SOURCE |
| SPRT | SOURCE est étayée par TARGET |
| CAUS | SOURCE cause l’observation de TARGET |
| GEVL | L’observation de SOURCE évalue le but de TARGET |
| MFST | SOURCE est la manifestation de TARGET |
| REFR | SOURCE se réfère à TARGET |
| SAS | SOURCE débute après TARGET |
| SUBJ | TARGET est le sujet de SOURCE |
L’attribut inversionInd (valeur booléenne) permet d’inverser la relation décrite par typeCode. Si l’on omet l’attribut inversionInd, alors on considère que inversionInd="false" (valeur par défaut).
Exemples :
typeCode="RSON" et inversionInd="false", alors TARGET est la raison de SOURCE.typeCode="RSON" et inversionInd="true", alors SOURCE est la raison de TARGET.Lorsqu’une donnée est obligatoire mais que l’on ne connaît pas la valeur de cette donnée lors de l’élaboration du document, il est possible d’utiliser un attribut nullFlavor qui permet d’indiquer la raison pour laquelle la valeur ne peut être fournie.
Par exemple, la date de début d’un problème est obligatoire (cardinalité [1..1]) mais le médecin ne la connait pas au moment de la rédaction du document. Dans ce cas, on peut utiliser un nullFlavor :
<low nullFlavor='UNK'>
Dans certains cas, l’utilisation de la valeur nullFlavor n’est pas autorisée pour obliger à fournir une valeur ayant une signification précise dans le contexte. Dans ce cas, les spécifications doivent préciser que l’utilisation du nullFLavor est interdite.
L’utilisation d’un nullFlavor n’est bien sûr utile que pour un élément obligatoire. Pour un élément facultatif, si la valeur n’est pas connue, il vaut mieux ne pas mettre l’élément.
Les valeurs les plus courantes pour nullFlavor sont les suivantes :
| Code | Libellé | Définition |
|---|---|---|
| NI | pas d’information | Valeur absente sans autre information. |
| OTH | autre valeur | Valeur existante, mais non prévue dans la liste proposée pour le codage de l’élément. |
| NINF | borne inférieure infinie | Borne inférieure infinie (pour des valeurs numériques PQ ou REAL). |
| PINF | borne supérieure infinie | Borne supérieure infinie (pour des valeurs numériques PQ ou REAL). |
| MSK | valeur masquée | Valeur masquée. |
| NA | pas de valeur applicable | Pas de valeur applicable dans ce contexte (par exemple, dernière période menstruelle pour un homme). |
| UNK | valeur inconnue | Valeur inconnue. |
| ASKU | demandé mais valeur inconnue | Demandé mais valeur inconnue (par exemple, information demandée au patient mais il ne savait pas). |
| NAV | valeur temporairement indisponible | Valeur temporairement indisponible. |
| NASK | non demandé | Information non demandée. |
| TRC | trace non quantifiable | Quantité présente à l’état de trace non quantifiable (pour des valeurs de type PQ ou REAL). |
Les documents au format CDA R2.0 définis dans le CI-SIS sont des documents XML qui doivent être conformes :
Les documents au format CDA R2.0 définis dans le CI-SIS doivent être valides par rapport au schéma CDA_extended.xsd qui regroupe le schéma CDA.xsd (partie intégrante de la spécification CDA R2.0) et les extensions internationales produites pour des domaines particuliers (ihelab.xsd, SDTC.xsd, POCD_MT000040_extended_pharmacy.xsd et DICOM.xsd).
Les documents au format CDA R2.0 définis dans le CI-SIS doivent être conformes aux exigences françaises de l’entête (Structuration minimale). Ces spécifications sont communes à l’ensemble des documents CDA produits en France.
Un document CDA R2.0 de niveau 3 (structuré) dont le modèle est défini dans le CI-SIS doit être conforme aux spécifications syntaxiques et sémantiques de ce modèle (Volet de contenus de la couche Métier) :
Une application productrice est autorisée à ajouter dans l’en-tête et dans le corps d’un document qu’elle produit des éléments non prévus dans le modèle dont se réclame le document, à condition que ces éléments restent conformes au standard CDA R2.0.
Une application consommatrice de document n’est pas tenue de traiter les éléments non définis dans le modèle, et dans le cas où elle ne les comprend pas, elle doit les ignorer.
En d’autres termes, ce n’est pas une erreur de mettre dans un document plus d’éléments que n’en spécifie le modèle ; en revanche c’est une erreur de rejeter un tel document.
Cette convention préserve la capacité aux implémentations d’apporter de la valeur ajoutée par rapport aux modèles.
Elle protège en outre la compatibilité ascendante, en permettant que des versions ultérieures d’un modèle apportant des éléments nouveaux, restent compatibles avec des implémentations qui ne connaîtraient qu’une version plus ancienne du modèle.
Cette convention est identique à celle définie par les cadres techniques IHE spécifiant des modèles de contenus. Elle est énoncée dans la section 2.3.1 du volume 2 du cadre technique IHE PCC.
L’ANS met à disposition des outils permettant de vérifier la conformité des documents CDA R2.0.
L’outil testContenuCDA à télécharger sur https://github.com/ansforge/TestContenuCDA-3-0/.
Il permet de vérifier en local la conformité d’un document CDA R2.0 aux spécifications françaises du CI-SIS.
L’espace de test est composé de deux outils :
Ces outils sont accessibles en ligne sur le site https://interop.esante.gouv.fr/ et notamment utilisés lors des Projectathons organisés par l’ANS pour les éditeurs.
Attention : l’espace de tests ne doit pas être utilisé pour vérifier la conformité de documents de production (produits pour un patient réel).
La vérification de la conformité d’un document CDA R2.0 se fait à l’aide de schématrons.
Les outils testContenuCDA et EVS Client permette de :
Pour vérifier la conformité d’un document CDA R2.0 de niveau 1 (corps non structuré), il faut utiliser le schématron “Structuration minimale”.
Ce schématron peut aussi être utilisé pour vérifier l’entête des documents CDA R2.0 de niveau 3 (à corps structuré).
Pour vérifier la conformité d’un document CDA R2.0 de niveau 3 (à corps structuré), il faut utiliser le schématron “ spécifique au modèle du document.
Par exemple : le schématron IPS-FR_2024.
Les documents au format standard CDA R2.0 sont visualisables au travers de l’IHM des logiciels de professionnels des secteurs sanitaire et médico-social ou des logiciels pour les patients.
Si le producteur du document CDA souhaite qu’une présentation spécifique soir respectée lors de la visualisation de son document, il peut intégrer une copie PDF du document dans le document CDA.
Le couplage d’une feuille de style personnalisée fournie par le producteur du document CDA est abandonné au profit de l’intégration d’une copie PDF dans le CDA. Cette solution de couplage d’une feuille de style personnalisée n’est donc pas présentée dans ce guide d’implémentation.
Certains documents CDA R2 N3 peuvent contenir une section spécifique FR-Document-PDF-copie (1.2.250.1.213.1.1.2.243) contenant une copie PDF du document.
Cette solution est utilisée pour permettre de toujours avoir une copie ayant la même mise en forme que le document remis au patient. Cette solution est notamment préconisée pour les CR d’examens de biologie médicale et les Prescriptions.
Dans ce cas, les systèmes consommateurs doivent en priorité afficher le document PDF contenu dans cette section FR-Document-PDF-copie (1.2.250.1.213.1.1.2.243).
A la demande de l’utilisateur, le système consommateur doit permettre de consulter le document CDA R2 N3 (voir paragraphe suivant “Visualisation avec une feuille de style (Transformation XSLT)”).
Le système consommateur (logiciel métier, interfaces web des SIS) porte la responsabilité d’offrir un rendu correct pour la visualisation des documents de santé : visualisation de l’entête CDA et des parties narratives du corps du document. Un document CDA étant un document XML, la présentation visuelle de ce document DOIT être pilotée par une feuille de style XSLT. Le système consommateur est libre d’utiliser sa propre feuille de style ou la feuille de style CDA-FO.xsl publiée à titre d’exemple dans testContenuCDA.
Si le document CDA contient une copie PDF du document, c’est le PDF qui DOIT être imprimé.
Sinon, l’impression du document au format CDA DOIT être réalisée par la transformation du document CDA en html (par la feuille de style XSLT) puis la transformation du fichier html obtenu en PDF/A-1.